This Blog is about Logistic Regression Algorithm.
Contents
1 模型原理
逻辑回归使用sigmod函数(如下图)对样本进行回归,之后设定阈值将正负样本分开,实际是一种分类算法。
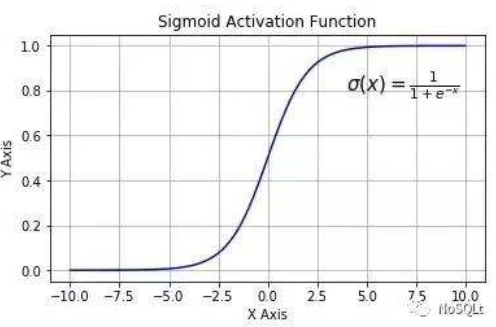
之所以选用sigmod函数,是由于逻辑回归可以看作是利用sigmod函数对后验概率P(y=1|x)的逼近(具体请见[1])。
2 问题背景
对于给定的m个样本(Xi, yi)(i属于[1,m],X为n维向量)进行二分类:y = 0为负例,y = 1为正例。
3 公式推导
3.1 假设函数(hypothesis function)
注:1) 其中θ表示模型的参数,即w,b;
3.2 预测正确的概率
我们将hθ(x)所给出的结果看作概率(因为sigmod可以将变量从(-∞,+∞)映射到(0,1)之间),即有:
注:1) p(correct)表示模型预测正确的概率:当y = 1即样本为正例时,p(correct) = hθ(x);当y = 0即样本为负例时,p(correct) = 1 - hθ(x)。
2)hθ(x)的意义:例如对于某患者是否为患病,hθ(x)输出结果为0.7,则表示患者未患病的概率为70%,患病的概率为30%。
3.3 最大似然估计
由于我们的目标是找到合适的θ使得所有样本的p(correct)最大,即使得模型预测正确所有样本的概率最大,所以我们采用最大似然估计:
连乘不好计算,所以我们对上式取对数:
最优化任务时习惯上我们希望得到函数的最小值,所以对上式取负,即是求解最小值,并得到我们最终的损失函数(交叉熵损失函数)J(θ):
3.4 最佳θ值计算
我们使用梯度下降计算损失函数的最小值,具体算法见[2],求解梯度(即损失函数偏导)的公式为:
其形式与最小二乘法梯度一致,区别在于最小二乘法中hθ(x) = WTx,也即是线性回归。